Much of the conversation around AI progress focuses on the top of the leaderboard — which model is best today. A different question is at least as interesting: how much has it cost, in parameters, to reach yesterday’s frontier?
The chart below takes three landmark GPT models — GPT-3, GPT-4, and GPT-5 — and traces every subsequent model that reached the same capability level. Each line is an “iso-performance” trajectory: a fixed benchmark score, plotted against release date and parameter count.
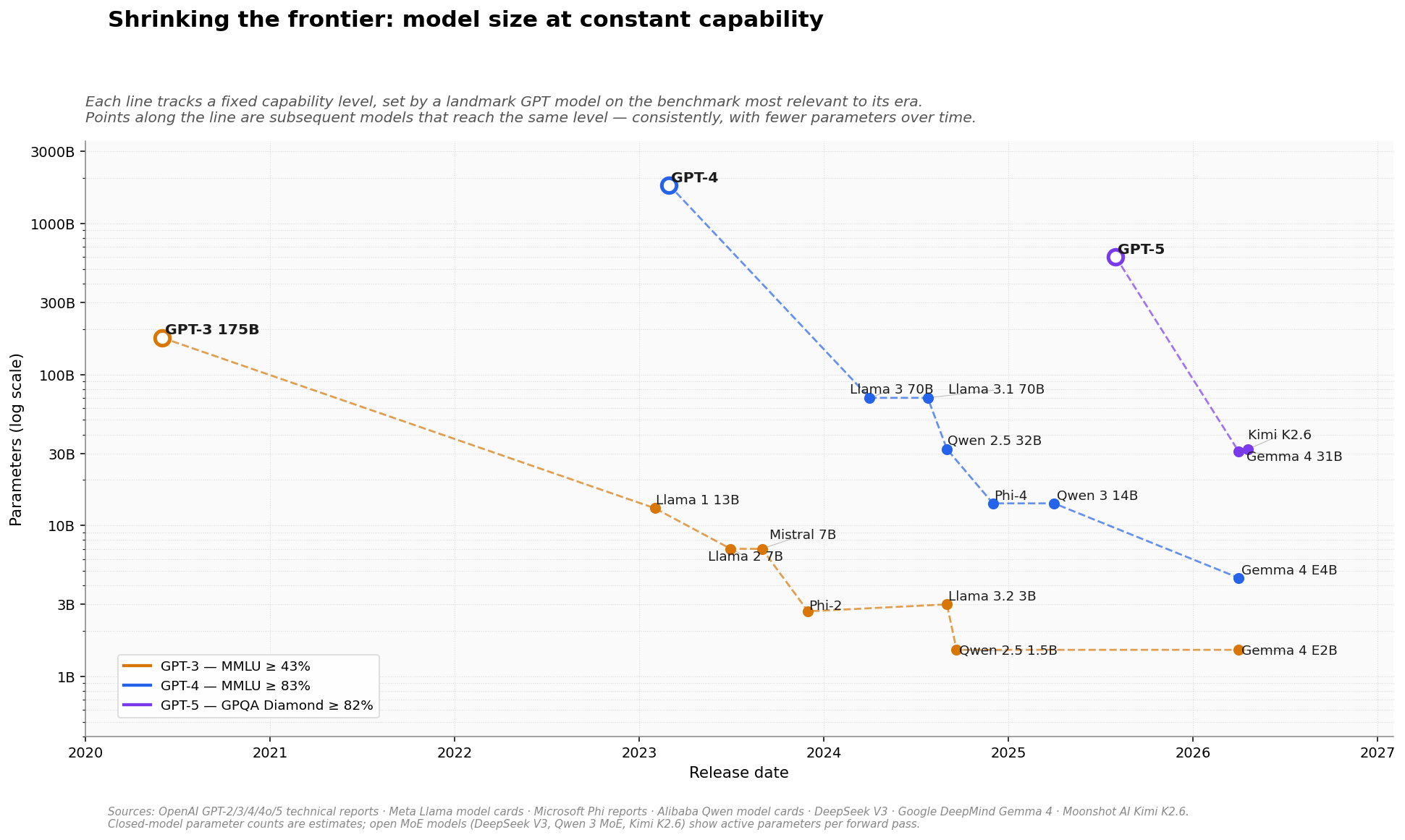
Each line tracks one capability level, set by a landmark GPT model on the benchmark most relevant to its era. Points along the line are later models reaching the same level. Source: AIF4T analysis, based on published benchmark results from OpenAI, Meta, Microsoft, Alibaba, DeepSeek, Google DeepMind, and Moonshot AI.
Reading the chart
Each line uses the benchmark most discriminating at its capability tier — MMLU for GPT-3 and GPT-4, and GPQA Diamond for GPT-5, since MMLU has saturated at the top. The threshold for entry onto each line is the landmark model’s own reported score. The y-axis is logarithmic; the “shrinking” is visible precisely because of it.
Three things stand out.
GPT-3: a 100× collapse in under five years
GPT-3 required 175 billion parameters in mid-2020 to reach ~44% on MMLU. By late 2024, Qwen 2.5 1.5B and Llama 3.2 3B were doing the same with roughly 1% of the parameter count. Gemma 4’s E2B, released earlier this month, continues the trajectory. The first real inflection came with Mistral 7B in late 2023 — a 25× reduction in barely three years — and the line has continued downward since. Better training data, distillation, and architectural improvements (grouped-query attention, sliding-window attention, improved tokenizers) all contributed.
GPT-4: three orders of magnitude in three years
This is the most dramatic line on the chart. GPT-4, with an estimated 1.8 trillion parameters at launch in March 2023, represented the extreme of the scale-first era. Three years later, Gemma 4 E4B reaches the same 86%+ MMLU level with 4.5 billion parameters — close to 400× smaller, small enough to run on a laptop. The trajectory is smooth rather than jumpy: Llama 3, Qwen 2.5 32B, Phi-4, and Qwen 3 14B all sit on the line, each shrinking the parameter count while holding the benchmark.
GPT-5: the new line has already started moving
GPT-5 launched in August 2025. Within eight months, two open-weights Mixture-of-Experts models — Gemma 4 31B and Kimi K2.6 — are already matching GPT-5’s GPQA Diamond score with 30–32 billion active parameters per forward pass. The line is sparse today, but the direction is already set. If the pattern holds from the two prior generations, the models that reach GPT-5’s capability level on a single laptop GPU should arrive in 2027 or early 2028.
Why this matters
We’ve covered several strands of the efficiency story across recent posts: the falling cost of frontier intelligence, Google’s TurboQuant compression breakthrough, and Moonshot AI’s consistently strong open-weights releases. The iso-performance lens above is the same story viewed from the parameter axis rather than the capability axis.
For anyone deploying AI — whether in financial research, enterprise workflows, or on-device applications — the implication is that what is economical today would have been impossible two years ago, and what is frontier today will be commodity within three. Model planning horizons need to account for this.
The frontier is not just moving. At every fixed capability level, it is shrinking.
Which begs a more uncomfortable question. If model capabilities are converging toward human-level intelligence, and the efficiency trend we describe here continues, will the world actually need all the compute and data centres currently being built to serve them? Training frontier models may continue to demand ever-larger clusters. But running them — the part that drives most of the long-term infrastructure demand — keeps getting cheaper, faster than almost any other technology curve in recent memory. It is worth keeping that second curve in mind when looking at the capital-expenditure plans being drawn up today.
Methodology note. Benchmarks are drawn from model creators’ published results under their reported evaluation protocols, which are not always directly comparable (shot counts, CoT usage, harness differences can all move scores by a point or two). Closed-model parameter counts for GPT-4 and GPT-5 are community estimates; the exact numbers are not disclosed. For open Mixture-of-Experts models (DeepSeek V3, Qwen 3 MoE, Kimi K2.6), active parameters per forward pass are shown — the figure that matters for inference memory and cost. Data is assembled from OpenAI technical reports; Meta Llama model cards; Microsoft Phi reports; Alibaba Qwen model cards; DeepSeek V3 paper; Google DeepMind Gemma 4 launch post; Moonshot AI Kimi K2.6 tech blog; and the MMLU, MMLU-Pro and GPQA benchmark papers.

Emmanuel Hauptmann is CIO and Head of Systematic Equities at RAM AI. He co-founded the company in 2007 and has led the development of the firm’s systematic investment and AI platform since.

