Efficiency, not scale, is now the main battleground in AI. In the last few weeks Google has advanced on two fronts, while Chinese lab Moonshot AI has once again raised the bar for open-source models. The common thread is clear: making frontier intelligence significantly cheaper to run.
We first flagged this direction in Shifting Frontier of AI Performance and Cost and in DeepSeek, Qwen and the Vanguards of Chinese AI. What’s happened since confirms the trend and accelerates it.
TurboQuant: significant compression without losing accuracy
TurboQuant, unveiled by Google Research, targets one of the main bottlenecks in modern LLMs: the memory cache that holds the model’s working context. As context windows stretch to hundreds of thousands of tokens, that cache has become the dominant cost of inference — often larger than the model weights themselves.
TurboQuant compresses this memory by roughly 6× with essentially no loss in accuracy, and without any retraining. The method relies on a companion technique called PolarQuant, which rotates data vectors into polar coordinates before encoding them — a geometric reshaping that makes low-bit quantization more stable. The same approach also extends to model-weight compression, meaning not just the working memory but the models themselves can be reduced in size while preserving quality.
The practical effect is significant: long-context models that previously required multi-GPU setups can now fit on a single GPU. It is the kind of engineering advance that reshapes what is economical to deploy — and sets the stage for Google’s next move.
Gemma 4: open, efficient, and highly capable
On April 2, Google DeepMind released Gemma 4, the fourth generation of its open-weights family, built on the same research foundation as Gemini 3. It comes in four sizes — two edge models for phones and laptops, a 26B Mixture-of-Experts, and a 31B dense flagship — all released under the permissive Apache 2.0 license.
The headline is intelligence-per-parameter. The flagship 31B ranks #3 among open models on the Arena AI leaderboard, competing with models roughly twenty times its size. The chart below — from DeepMind’s own launch post — illustrates this more clearly than any table of benchmarks:
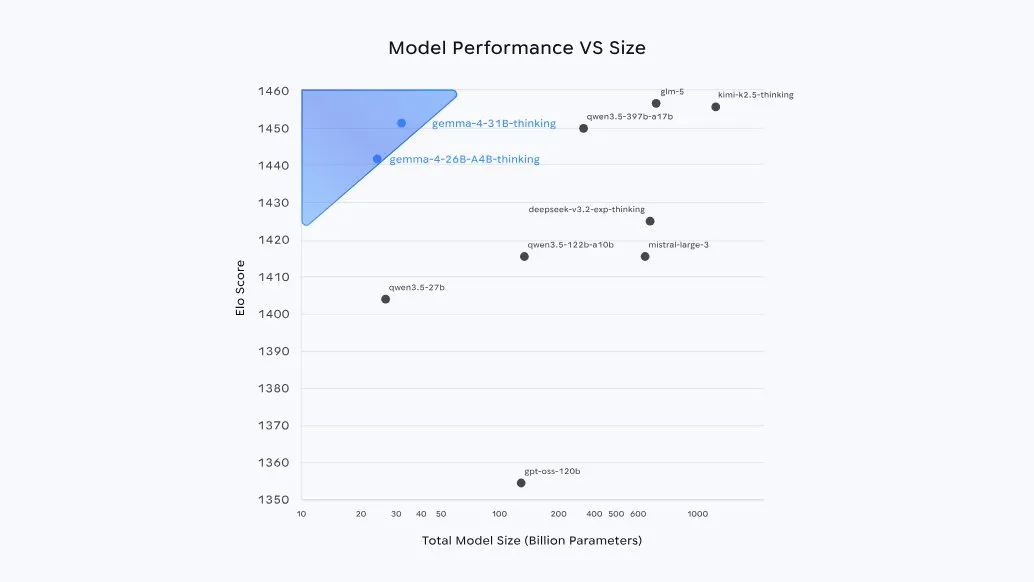
Gemma 4 defines a new Pareto frontier at smaller sizes. Source: Google DeepMind — Gemma 4 launch post.
The generational progress over Gemma 3 is significant: on competition math (AIME 2026), the model goes from roughly 20% to nearly 90%. Coding and agentic tool-use benchmarks show improvements of a similar magnitude. The architecture — alternating local and global attention, shared key-value cache, per-layer embeddings — has been deliberately designed to be quantization-friendly. The pairing with TurboQuant is no accident.
The race: US vs. Chinese labs
While Google was shipping, Chinese labs did not stand still. Two days ago, on April 20, Moonshot AI released Kimi K2.6 — the successor to the K2 Thinking model we covered in November. Same formula as its predecessor: a trillion-parameter Mixture-of-Experts model, open weights, natively quantized to INT4 for efficient inference.
According to Artificial Analysis, K2.6 is the leading open-weights model in the world, sitting just behind the top proprietary systems from Anthropic, Google and OpenAI — and ahead on several agentic and coding benchmarks.

Kimi K2.6 versus the top proprietary models. Source: Moonshot AI — Kimi K2.6 Tech Blog.
The pattern we described a year ago has now taken clearer shape. Chinese labs are shipping open-weights models at the efficient frontier, natively quantized and tuned for agentic use. US labs are responding not by racing on scale, but by releasing smaller, tighter, increasingly open systems — and by publishing the underlying efficiency primitives, like TurboQuant, for free.
For users, the outcome is positive: the cost per unit of intelligence continues to decline, open models are credible frontier competitors, and the hardware barrier to running a SOTA-class system keeps lowering. The frontier we wrote about in early 2025 is still moving — and the pace is accelerating.
At RAM AI we track these developments closely, particularly where they intersect with the systematic investment workflows we run on long-context retrieval and agentic pipelines. Learn more at ram-ai.com.

Emmanuel Hauptmann is CIO and Head of Systematic Equities at RAM AI. He co-founded the company in 2007 and has led the development of the firm’s systematic investment and AI platform since.

