s1: Simple test-time scaling
What better test of the adage ‘Think twice before speaking’?
By instructing LLMs to pause and take more compute time before providing their answer, their output quality improves significantly!
Researchers from Stanford University, University of Washington Seattle, Allen Institute for AI and Contextual AI show that a fine-tuned Qwen language model forced to take extra compute-time significantly improves its reasoning skills at many benchmarks.
Check it out:
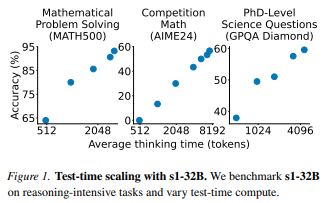
Source: s1: Simple test-time scaling [2501.19393v1] s1: Simple test-time scaling

Emmanuel Hauptmann is CIO and Head of Systematic Equities at RAM AI. He co-founded the company in 2007 and has led the development of the firm’s systematic investment and AI platform since.

