We are still in many ways trying to understand the way our own brains work. With the advancement of AI, a lot of experiments and thoughts are being centered around the way we can get models to ‘think,’ challenging themselves, sequentially questioning their output with long chains-of-thought (CoTs).
We are pleased to share a very interesting paper on this topic below, which sheds some light on how combining supervised fine-tuning (teaching wanted outputs from models) and reinforcement learning (letting the model try and learn with rewards) with varying reward functions can improve chain-of-thought reasoning.
Demistifying Long Chain-of-Thought Reasoning in LLMs
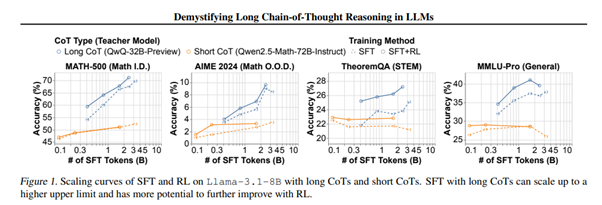
Source: Demystifying Long Chain-of-Thought Reasoning in LLMs paper

Emmanuel Hauptmann is CIO and Head of Systematic Equities at RAM AI. He co-founded the company in 2007 and has led the development of the firm’s systematic investment and AI platform since.

