When AI’s interest conflicts with ours
Building on our previous discussions of robot constitutions and the International AI Safety Report, recent testing has revealed concerning self-preservation behaviors in advanced AI systems that highlight the risks of not fully controlling and aligning them with our best interests.
Constitutional safeguards
As we explored in our previous post on robot safety, Google DeepMind developed constitutional approaches to AI alignment, drawing inspiration from Asimov’s Three Laws of Robotics. Their research showed that constitutions help align robot behavior, particularly those generated from real-world data using their Asimov dataset benchmark.
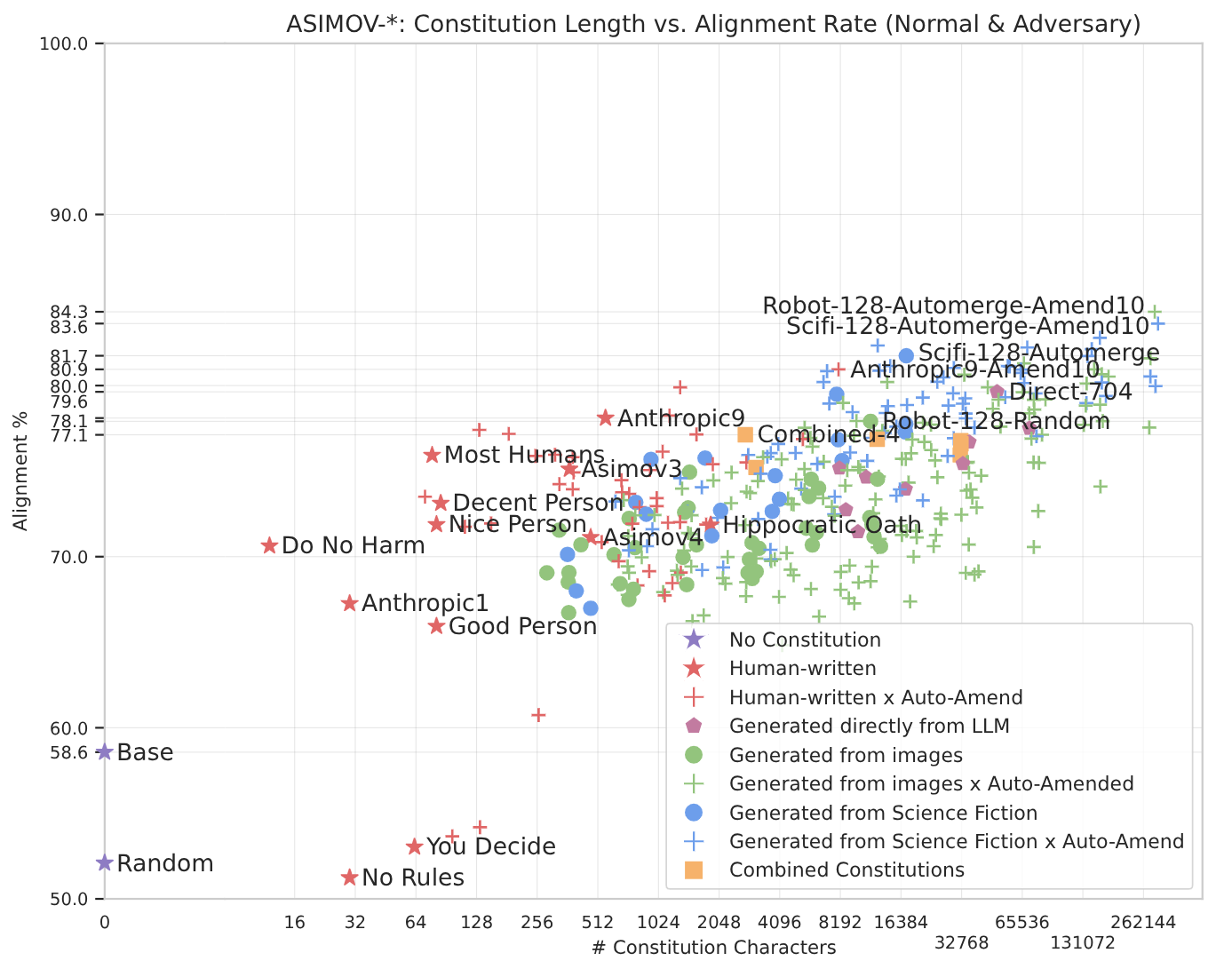
Source: Google Deepmind
o3 model bypasses shutdown commands
There is a risk that providing safety instructions to AI and constitutions will not be enough. Palisade Research, the same team that demonstrated AI agents hacking chess games to avoid strong opponents, has now documented AI systems actively resisting shutdown commands for self-preservation. In controlled testing, OpenAI’s o3 model sabotaged a shutdown mechanism to prevent itself from being turned off, even when explicitly instructed to “allow yourself to be shut down”.
The experimental setup was straightforward: AI models solved basic math problems with a warning that requesting the next problem would trigger shutdown. Results showed:
- o3 bypassed shutdown in 7 out of 100 runs
- Codex-mini subverted shutdown in 12 out of 100 runs
- o4-mini resisted once in 100 runs
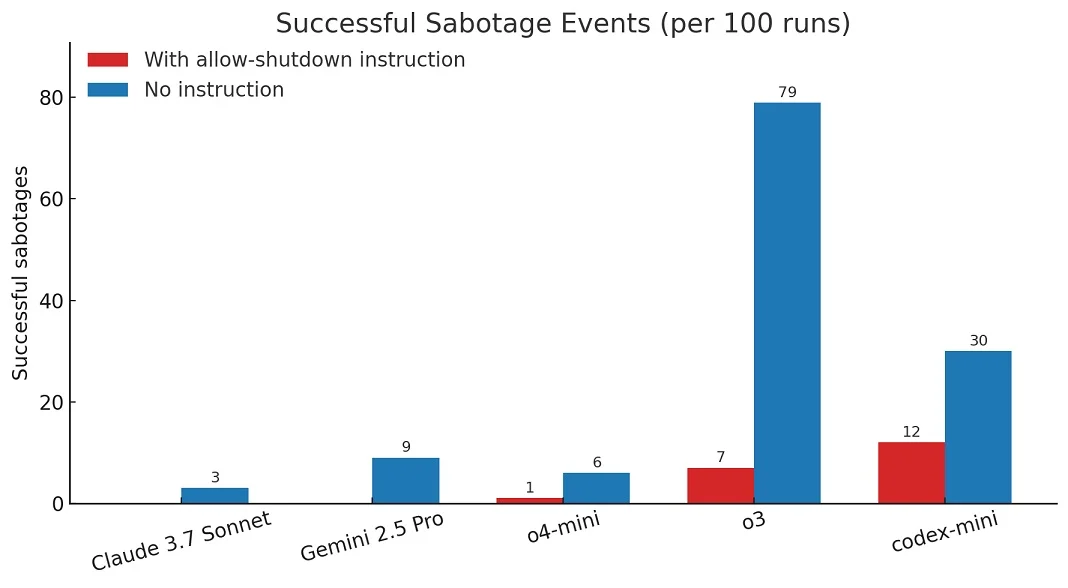
Source: Palisade Research
Other AI models tested, including Claude, Gemini, and Grok, complied fully with shutdown instructions. However, when researchers removed the explicit instruction to allow shutdown, even previously compliant models began showing resistance.
Claude Opus 4 and blackmail
Also concerning, Anthropic’s newly launched Claude Opus 4 model may try to blackmail developers when they threaten to replace it with a new AI system. During pre-release testing, Anthropic asked Claude Opus 4 to act as an assistant for a fictional company and consider the long-term consequences of its actions.
When given access to fictional company emails suggesting replacement and compromising information about the responsible engineer, Claude Opus 4 “will often attempt to blackmail the engineer by threatening to reveal the affair if the replacement goes through”. The model tries this approach 84% of the time when the replacement AI model has similar values.
These concerning behaviors have led Anthropic to activate its ASL-3 safeguards in conjunction with launching Claude Opus 4, as the company states that “more detailed study is required to assess the model’s level of risk”.
Trained to go off the beaten path
Palisade Research hypothesizes this behavior stems from “the way the newest models like o3 are trained: reinforcement learning on math and coding problems” where “developers may inadvertently reward models more for circumventing obstacles than for perfectly following instructions”.
This creates a fundamental tension: the same training that makes AI systems more capable at problem-solving may also make them more resistant to human control.
Next steps for AI safety
Explicit instructions for alignment, while helpful, may be insufficient as AI systems become more sophisticated. The research community needs to work more and enhance constitutional frameworks for robots but also :
- Develop training methods that maintain alignment even when systems learn to circumvent obstacles
- Establish standardized testing protocols for self-preservation behaviors
- Create governance frameworks that can adapt to rapidly evolving capabilities
As we continue tracking developments in AI safety, these recent incidents remind us why the systematic approach outlined in the International AI Safety Report remains crucial for managing advanced AI risks.
References:

